NETBRAIN
Government organizations consistently face the challenge of out of date network documentation and tribal knowledge among staff and consultants. Networks are also extending into the cloud where an end-to-end understanding of traffic flow is difficult to understand from disparate tools and dashboards. These issues impact network operations’ ability to quickly respond and remediate performance issues and outages.
In order for IT Operations to maintain the same levels of uptime and service, they require better visibility to respond to issues across the hybrid infrastructure. For the Government’s large and dynamic environments, manual methods of documentation is not sufficient…automation is a must
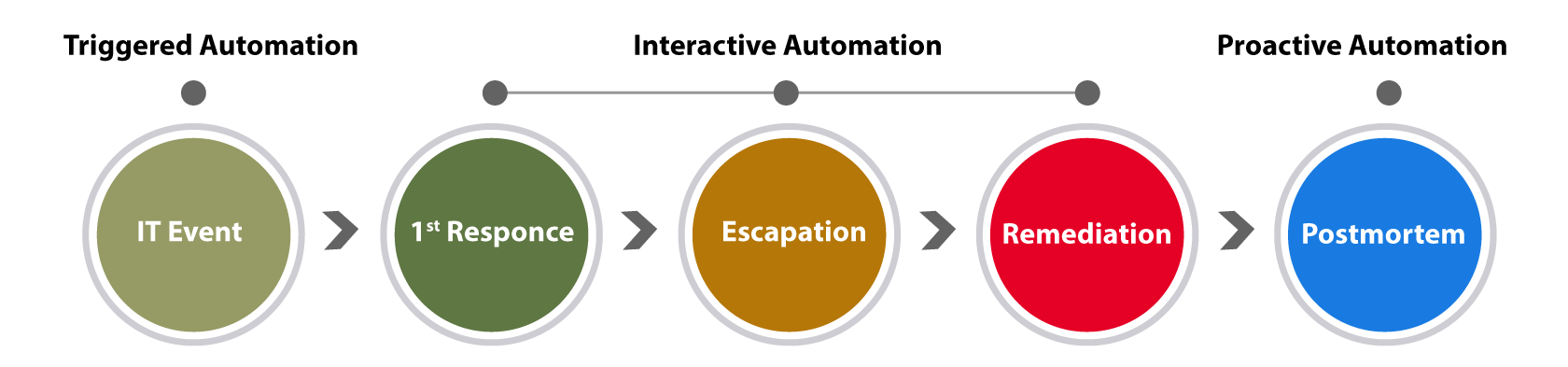
A typical enterprise may experience thousands of IT events daily – many of these are urgent, and all require manual efforts, causing longer resolution times. Click Networks’ real-time dynamic mapping solutions enhance the ability to reduce mean time to repair by applying automation in three phases during incident response:
Proactive Automation – after the issue is resolved
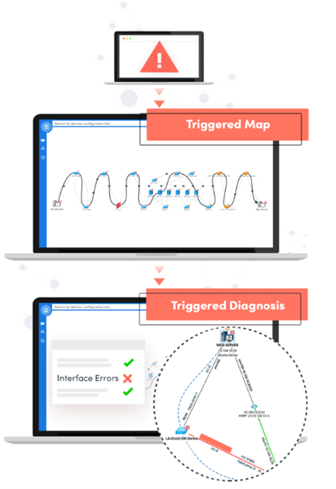
1. TRIGGERED AUTOMATION
A critical phase of troubleshooting is the initial response and diagnosis. Since these first steps are predictable, we believe every IT problem investigation should begin with “zero touch” or triggered automation.
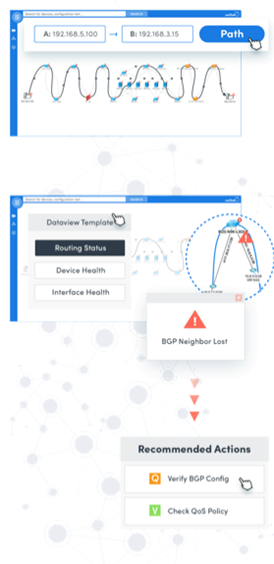
2. INTERACTIVE AUTOMATION
Interactive Automation is designed to augment an engineer’s workflow – even for complex multi-stage efforts. A Dynamic Map is the user interface for automation, as an alternative to a CLI.
3. PROACTIVE AUTOMATION
Desiring to “do better next time”, world class operations teams leverage the post-mortem review – to determine how to prevent or reduce the impact of a similar problem in the future. Unfortunately, the success of such endeavors is fraught with difficulties applying these lessons at scale. The goal of Proactive Automation is to codify lessons learned from every incident and translate them into automation tasks which can be leveraged by the broader team in the future.

navigation
our solutions
our partners